

昔时两年,淌若要找一个在黄仁勋演讲中出现频率越来越高的词,除了GPU,八成便是基础设施。
从AI Factory到GB300,再到下一代AI集群,NVIDIA延续描述着归拢个趋势:算力限制仍在持续扩大。而每一次算力密度升迁的背后,齐伴跟着另一个数字同步增长——功耗。当单机柜功耗向百千瓦迈进,散热运行从数据中心后台的工程问题,变成影响算力部署限制的病笃变量。
液冷因此走到了产业舞台中央。
围绕液冷伸开的新投资、新技俩和新时间延续涌现,职业器厂商、数据中心运营商、暖通企业和设备供应商齐在从头寻找我方的位置。
尼得科亦然其中之一。
不外,与很多从制冷或热管束范畴切入液冷的企业不同,这家以电机起家的制造企业看到的,是另一条时间旅途。
“咱们所以电机起家的企业,泵时间才是液冷的病笃基础之一。”在上海IDCExpo时刻,尼得科株式会社袖珍马达职业本部本部长,AI & IT职业部 部长,商品开发第二统括部部长 田中裕司这样施展谈。

尼得科株式会社袖珍马达职业本部本部长,
AI & IT职业部 部长,商品开发第二统括部部长 田中裕司
这句话背后,其实对应着AI基础设施开导正在发生的变化。
昔时,当液冷还只是少数高密度场景的聘任时,东谈主们更照拂冷板、换热器和散热才调本人。而跟着液冷渐渐走向限制化部署,系统可靠性、历久运行才调以及运维遵循运行变得越来越病笃。
关于领稀有千块GPU的AI集群来说,把热量带走只是第一步。真实的挑战在于,怎样让整个这个词液冷系统在历久运行经由中遥远保持端庄的流量、压力和冷却遵循。
这恰正是泵阐扬作用的方位,亦然尼得科最见长的范畴。更是尼得科看待液冷市集的起点。
关于一家历久从事电机和泵居品研发制造的企业来说,AI基础设施带来的液冷需求,并非全新的时间命题,而是原有才调在新应用场景下的一次开释。
01 入局液冷赛谈,尼得科的“两张底牌”
关于尼得科而言,液冷并非“从零运行”的跨界。电机、泵、精密制造,以及长达20余年的职业器散热范畴劝诫,这些才调早已存在。跟着AI基础设施全面进入液冷期间,这些才调在归拢场景下鸠集,而鸠集的第一个载体,正是CDU(冷量分拨单位)。
尼得科的第一张牌,是把“车规级”的泵,放进数据中心。CDU的中枢部件是泵,而泵的实践又离不开马达,这恰恰是尼得科最擅长的范畴。
田中裕司走漏,尼得科CDU中的中枢泵体,沿用了车载零部件范畴积贮的车规级泵时间。
这背后的逻辑在于,汽车历久濒临滚动、高下温变化以及持续运行等复杂工况,对零部件可靠性和寿命的条目不时高于恒温恒湿的数据中心环境。换句话说,把正本为汽车场景想象的居品应用到机房,本人便是一种“才调降维”,阅历过更严苛考验的系统,在相对端庄的环境中不时能够得到更大的可靠性余量。
基于这一想路,尼得科将车规级无密封泵引入CDU,并集结自主开发的电机驱动与泵控时间,构建起液冷系统最中枢的轮回才调。比较单纯采购范例水泵再进行系统集成,这种决策的上风在于,泵体、驱动和厌世系统从底层运行协同想象,能够在历久运行中保持更端庄的流量厌世和更高的系统可靠性。
而这种底层可靠性,最终会体当今整个这个词液冷系统的想象余量上。
以第二代In-Rack CDU为例,其4U机型最高可提供250kW散热才调,单台设备即可粉饰一整套NVIDIA HGX B300系统,而GB300机柜实践冷却需求也独一约144kW。也便是说,在骄贵面前需求以外,系统仍保留了相当可不雅的散热空间,以顶住畴昔硬件升级、负载波动,以及历久运行经由中可能出现的性能衰减。

相通的高可用想象理念也体当今系统架构层面。尼得科在泵体、电源和厌世板等关节部件上均继承冗余想象,并维持热插拔珍摄,从而在居品架构想象阶段就齐备了“不休机珍摄”的狡计。
从车规级泵时间到系统级冗余想象,尼得科将汽车产业积贮数十年的可靠性工程劝诫,迁徙到AI数据中心液冷基础设施之中。
第二张牌是把精密制造劝诫搬进液冷系统。泵是液冷的腹黑,决定系统能否运转;而快盘考则是命门,它胜仗决定了机柜里动辄数千万的GPU算力钞票,会不会毁于渗液风险。
其实,液冷大限制部署的除了是散热瓶颈,还有漏液风险。在这一措施,工程容错率趋近于零,一朝快盘考出现问题,冷却链路瘫痪,会将导致底层AI职业器胜仗打消。
尼得科的解法是,诈欺我方最中枢的硬盘马达劝诫。行动精密制造的“金字塔尖”,硬盘主轴马达对微米级加工、极限密封与洁净度有着严苛条目。尼得科将这套千里淀了数十年的重钞票体系平移,Class 100级无尘车间、油压密封工艺、高精度数控机床,被统统导入快盘考的产线。
终结上,数据也组成了有劲的复兴。面前,尼得科UQD和MQD系列快盘考累计出货超 75 万对,于今保持零漏液。
在分娩上,为了让零漏液的加工精度不出现任何批次毛病,尼得科聘任胜仗受购日本老牌机床企业泷泽(TAKISAWA)。“用我方的车床加工,才敢保证零袒露。”田中裕司抒发了尼得科的战术想路。与其满天下采购通用设备去死磕良率,不如胜仗把微米级加工的标尺紧紧持在我方手里。
当车规级电机的底座、硬盘产业的精密加工,与自研机床托底的品控体系酿成闭环时,一条高壁垒的护城河就此成型。

02 可堆叠CDU破解制冷“两难”
结实了这些时间积贮,再看尼得科首秀的重磅居品:STC 1.0样机,不觉振振有词。
在液冷范畴,数据中心运营商历久濒临两难的场面。一方面,滚球app网页2026最新版AI芯片迭代太快,今天部署200kW的CDU,来岁新一代GPU上架后制冷才调可能就运行吃紧。然而,淌若一步到位上1MW级别设备,又容易出现过度确立情况。
STC 1.0惩办的正是这个问题。
STC 1.0给出的想路是把CDU作念成可堆叠的模块化架构。这款CDU合适OCP范例、最多维持5层堆叠的In-Rack CDU。用户不错先部署单层模块骄贵面前需求,跟着算力限制增长,再迟缓增多新的制冷单位。

“咱们的想象允许客户按热负荷纯真膨胀。”田中裕司施展。初期只需运行1层200kW模块,畴昔算力扩大,再通过热插拔边幅增多第2层、第3层,最高可堆叠至5层,齐备1MW冷却才调。通过定制机架表率,致使能够膨胀至8层、1.6MW。
每层单位结构零丁,单层故障可单独结巴而不影响其他模块;趋近温度作念到4℃,适配OCP ORV3范例机架,系统运行时刻即可完成CDU单位更换。关于运营商来说,这意味着扩容和珍摄齐无须再以停机为代价。
事实上,STC 1.0是尼得科In-Rack阶梯持续演进后的效果。
往前回看整条居品线,节律其实相称显着。EIA规格的Gen 1.0(200kW,对应NVIDIA HGX B200)、Gen 2.0(250kW,对应B300);OCP规格的Gen 2.5(250kW/160LPM,对应GB300 NVL72,维持51VDC母线输入、兼容NVIDIA MGX);再到Gen 3.0(300kW/280LPM,适配OCP ORV3,维持最新GPU平台);最终发展到可堆叠膨胀至1MW的STC 1.0。

一代接一代居品升级,对应的是GPU功耗延续高潮后,液冷系统在制冷才协调流量上的持续升迁。
而当机架功率连续进取时,仅靠In-Rack还是无法粉饰整个场景,于是尼得科又把才调延长到了In-Row居品。
尼得科NIR 2.5和Project Deschutes 5,齐属于2MW级列间CDU。前者达到2MW/2250LPM,后者达到2MW/1890LPM,并还是通过Google认证。换算到实践部署场景,一台设备就足以撑持10台NVIDIA NVL72机柜,或者6台下一代超高密度Vera Rubin,NVL72机柜的散热需求。


某种程度上说,这一台CDU还是能够承担起一个袖珍AI算力集群的冷却任务。
除了功率限制,两款居品在运维想象上也延续了尼得科一贯的想路。
百人牛牛电子app2026中国最新版NIR2.5机身高度1.9米,占大地积相对紧凑,可适配集装箱数据中心部署,最多维持10台CDU集群联控,无密封结构泵体维持运行经由中完成滤网清洁和中枢部件热插拔。
Project Deschutes 5则进一步强化了系统端庄性。该居品配备合适IEEE 519范例的ULHD(超低谐波失真)VFD,用于保险供电质料,同期通过0.2μm旁途经滤系统持续看护冷却液洁净度。
03从“作陪出海”到押注中国液冷市集
田中裕司展示的一张人人售后体系舆图,走漏出了尼得科在人人市集的近况。舆图中,蓝色代表还是插足运营的职业网点,绿色代表狡计开导中的网点。中国区域面前仍骄矜为绿色。
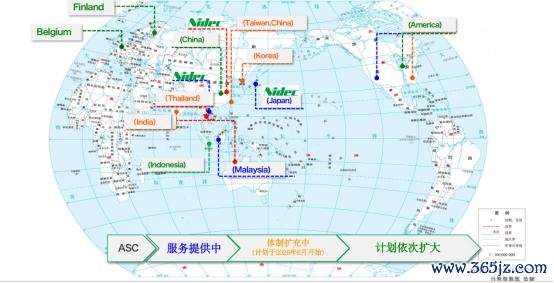
这并不料味着尼得科缺席中国市集。
事实上,尼得科还是与不少中国互联网企业和职业器厂商建立合营。只是现阶段,这些合营更多发生在数据中心的出海技俩中。致使,尼得科很早就参与了中国企业的出海程度。
关于液冷行业而言,这样的旅途并不难结实。
数据中心客户采购的除了设备本人,还包括备件供应、故障反应、现场珍摄,以及历久运维才调。比较还是建立起锻真金不怕火职业体系的国际市集,中国脉土职业网罗的开导彰着还有不少责任要完成。
不外,职业体系仍在开导,并不料味着尼得科在中国败落基础。
依托原有袖珍马达业务积贮下来的制造才调,尼得科还是在中国建立了1个时间开发中心(大连时间开发中心)和 3个制造基地(尼得科电机浙江、尼得科电机韶关、尼得科电机东莞)
比较职业网罗,更值得照拂的是尼得科对中国算力市集变化的判断。
昔时几年,人人液冷产业的发展旅途,很大程度上是围绕NVIDIA GPU演进伸开的。从H100到B200,再到GB300,职业器架构和散热需求天然持续变化,但举座时间阶梯相对一致。
“而中国市集是另一种情况。”田中裕司如是说
跟着国产GPU迟缓进入考验和推理场景,越来越多原土厂商运行探索新的集群架构。而濒临机柜里面的管路想象、流量分拨、压力厌世,以及热门管束的变化,对液冷系统也建议了不同条目。
按照田中裕司的先容,高密度冷板想象和±1℃级别的精确控温才调,齐是围绕高密度GPU集群开发的。当一个节点里堆叠的GPU越来越多,其挑战便不单是产生了若干热量,而是怎样让冷却液均匀流经每一个节点,把热量端庄带走。
关于数据中心运营商来说,散热才调是第全部门槛,运行老本相通病笃。
田中裕司提到,昔时数据中心的一、二次侧热轮回多数依赖冷水机组,天然能够提供端庄制冷才调,但能耗并不低。跟着液冷迟缓普及,越来越多数据中心运行尝试引入湿热却器等天然冷却决策,但愿进一步降顽劣源亏蚀。
但天然冷却并不单是把冷水机组换掉这样肤浅。
当外部环境变化更大、系统转念空间变小时,CDU关于流量厌世和温度厌世的条目反而会进一步提高。换句话说,越想降顽劣耗,越考验液冷系统本人的端庄性。
按照尼得科提供的数据,传统风冷数据中心的PUE频繁在1.6至2.0之间,而液冷决策还是能够作念到1.1至1.2,举座能耗降幅约为40%。
当AI数据中心运行以数十兆瓦致使上百兆瓦的限制部署时,PUE每下落0.1,最终齐会体当今运营老本上。
除了降顽劣耗,尼得科也在尝试惩办液苦处地经由中的另一个现实问题:客户怎样考证效果。
田中裕司共享了还是在日本落地的合营风物。具体来说,技俩由尼得科提供CDU和液冷基础设施,理想日本提供职业器平台,第三方数据中心运营商MC Digital提供真实机房环境。客户不错胜仗在实践运行的数据中心里不雅察职业器与液冷系统协同责任的现象,并不单是依赖实验室测试数据。
关于仍处于快速发展阶段的液冷市集来说,这样的考证不时比参数表更有劝服力。
按照尼得科的狡计滚球app网页2026最新版,近似合营畴昔也将迟缓膨胀至中国过甚他地区。

 备案号:
备案号: